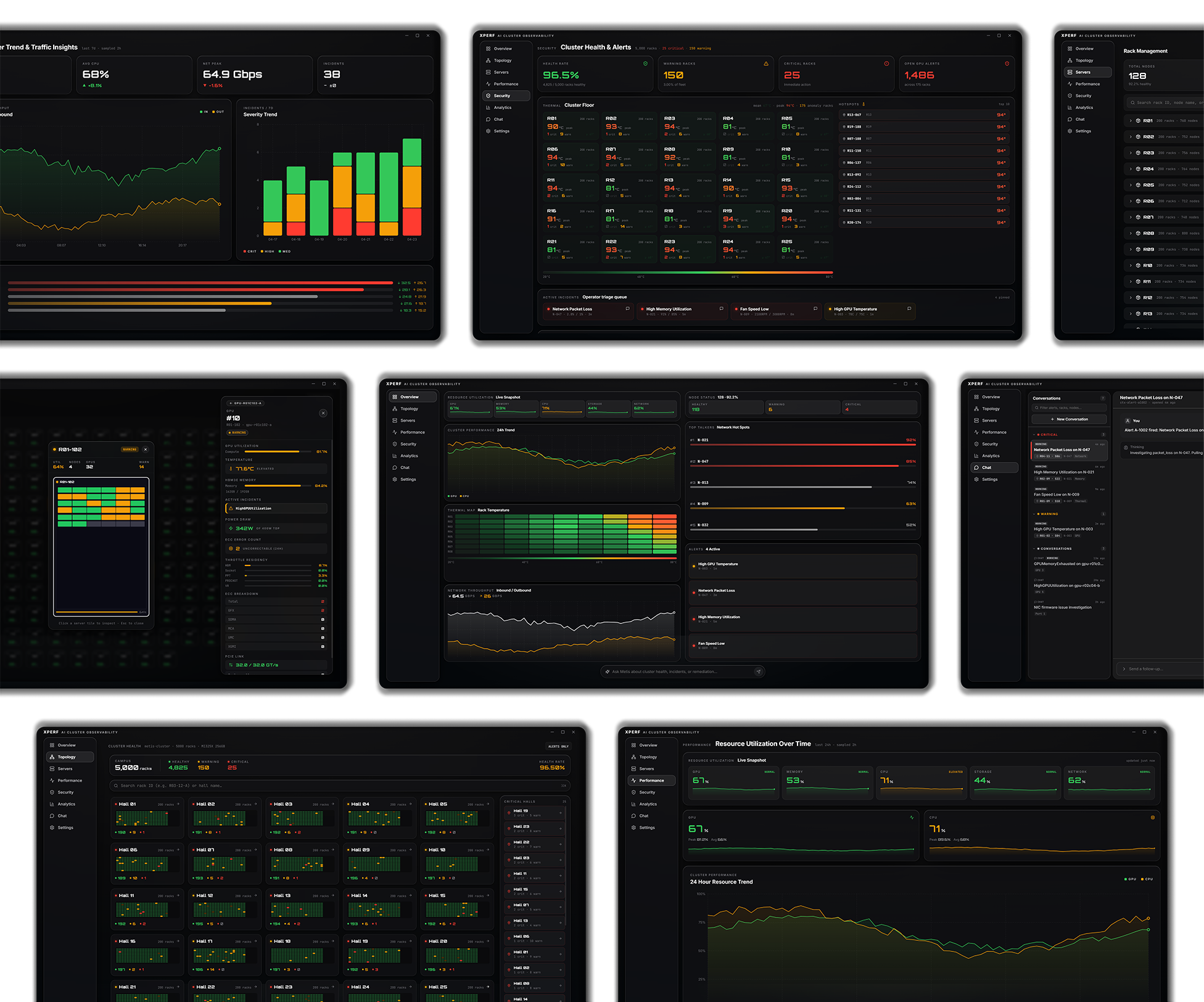
AI Cluster Reliability, Automated.
An AI-native operations system that continuously monitors your AI clusters, finds problems before they cause downtime, and fixes them automatically.
AI Clusters Fail Frequently
Reactive alerting & no failure prevention.
Manually triages hundreds of alerts.
Every failure is diagnosed from scratch.
A rack is down = $1,000s/hour lost revenue.
419 interruptions in 54 days. 54%+ caused by GPU or memory hardware failures.
OpsPilot closes this gap.
OpsPilot
An AI-native operations system that continuously monitors your AI clusters, finds problems before they cause downtime, and fixes them automatically.
Failure Prevention
Safe Operating Envelope through calibration. Continuous monitoring & failure prediction. Auto-recalibration when drifts are detected.
Diagnosis & Remediation
Issue detection and root cause identification. End-to-end self-healing through AI agents. Learning from every incident.
Enterprise-Grade Security
On-premise deployment — data never leaves your facility. Enterprise guardrails on every action. Human-in-the-loop for critical actions.
Four Stages. Fully Automated.
OpsPilot works continuously in the background. No manual intervention for routine issues.
Calibrate
Establish performance baselines. Define Safe Operating Envelope. Build physical models for failure prediction.
Monitor
Catch anomalies in real-time. Detect drifts before problems happen. Predict failures.
Diagnose
Pinpoint root cause in minutes via XPerf-trained AI agent. Analyze telemetry trends to identify issues. Reuse knowledge from past incidents.
Intervene
Prevent: take preventive actions and recalibrate when hardware drifts. Remediate: apply proven fix, requiring manual approval for critical actions.
A Safety Model for Every Node.
OpsPilot learns each node’s behaviour on day one, forecasts trouble 10–30 minutes ahead, and applies the lightest action to keep it safe.
A safety model per node on Day One
A one-hour calibration captures how the node behaves under load. Generic limits give way to its real boundaries.
See trouble 10–30 minutes early
OpsPilot projects each node's path and steps in with the lightest action. Training keeps running.
Refreshes the forecast every cycle
OpsPilot recomputes each node's forecast every few seconds with the latest telemetry, using the same per-node model.
A Coordinated Fleet. Self-Adapting at Scale.
Beyond each node, OpsPilot watches the whole fleet as one system. And it retunes those models whenever the system changes.
Catch failures no single node would see
OpsPilot surfaces cluster-wide drift, like hot and cool zones forming across racks, even when every node still looks healthy on its own.
Retunes when the system changes
Hardware aging, config updates, component swaps. OpsPilot widens safety margins live and queues a full recalibration when needed.
Failures caught before they cascade. Models that stay accurate as the cluster evolves.
Alert to Resolution
What used to take an on-call engineer hours of manual triage now runs end-to-end in minutes — fully autonomous, with you reviewing the audit trail.
- Alert fires at 3 AM.
- On-call engineer wakes up.
- Manually checks dashboards, logs, etc.
- Searches for similar past issues.
- Applies a fix, monitors, hopes it holds.
- Alert fires. OpsPilot picks it up instantly.
- Automatically queries cluster telemetry.
- Cross-references with past incidents.
- Identifies root cause within seconds.
- Applies proven fix, requires approval for critical changes.
Your Data Center, Your Data. Operating Securely.
- Runs entirely inside your infrastructure.
- No cloud dependency. Works even offline.
- Meets data sovereignty and compliance.
- Cluster telemetry never transmitted externally.
- Human-in-the-loop for critical actions.
- Input guardrails prevent misuse & injection.
- Output guardrails. No sensitive data exposed.
- Full audit trail on every action taken.
The More You Use It, The Smarter It Gets
- Every resolution stored with root cause and fix.
- Auto-recalls similar past incidents.
- Diagnosis accelerates over time.
- Never forgets, never leaves the company.
- Baselines from calibration.
- Continuously monitors for drifts.
- Predicts failures and improves safe operating envelopes.
- Auto-recalibrates as hardware evolves.
The only AIOps system with ground-truth performance models for your specific hardware.
See OpsPilot in action
ClusterReady is now integrated into OpsPilot
ClusterReady handles day-0 calibration and ongoing re-calibration. OpsPilot uses that baseline to run the cluster safely day after day.
Comparison
| Capability | NVIDIA NVSentinel | Grafana AI | Penguin ICE | Nebius Soperator | OCI GPU Scanner | Resolve.ai | 2501.ai | OpsPilot |
|---|---|---|---|---|---|---|---|---|
| Hardware aware | Yes | Partial | Yes | Yes | Yes | No | No | Yes |
| On-premise | Yes | No | Yes | Yes | Yes | No | Yes | Yes |
| Predictive | No | Partial | Yes | No | Partial | No | No | Yes |
| AI diagnosis | No | Yes | Yes | No | No | Yes | Yes | Yes |
| Learns + HITL | No | No | No | No | No | Partial | No | Yes |
| Serves any data center | Yes | No | Partial | No | No | No | Yes | Yes |
| Limitation | No reasoning, no predictive | No GPU depth, no memory | Engineer service dependent | Nebius locked | Oracle locked | SaaS only | Not applicable to GPU | — |
- Hardware aware
- Yes
- On-premise
- Yes
- Predictive
- Yes
- AI diagnosis
- Yes
- Learns + HITL
- Yes
- Serves any data center
- Yes
- Limitation
- —
- Hardware aware
- Yes
- On-premise
- Yes
- Predictive
- No
- AI diagnosis
- No
- Learns + HITL
- No
- Serves any data center
- Yes
- Limitation
- No reasoning, no predictive
- Hardware aware
- Partial
- On-premise
- No
- Predictive
- Partial
- AI diagnosis
- Yes
- Learns + HITL
- No
- Serves any data center
- No
- Limitation
- No GPU depth, no memory
- Hardware aware
- Yes
- On-premise
- Yes
- Predictive
- Yes
- AI diagnosis
- Yes
- Learns + HITL
- No
- Serves any data center
- Partial
- Limitation
- Engineer service dependent
- Hardware aware
- Yes
- On-premise
- Yes
- Predictive
- No
- AI diagnosis
- No
- Learns + HITL
- No
- Serves any data center
- No
- Limitation
- Nebius locked
- Hardware aware
- Yes
- On-premise
- Yes
- Predictive
- Partial
- AI diagnosis
- No
- Learns + HITL
- No
- Serves any data center
- No
- Limitation
- Oracle locked
- Hardware aware
- No
- On-premise
- No
- Predictive
- No
- AI diagnosis
- Yes
- Learns + HITL
- Partial
- Serves any data center
- No
- Limitation
- SaaS only
- Hardware aware
- No
- On-premise
- Yes
- Predictive
- No
- AI diagnosis
- Yes
- Learns + HITL
- No
- Serves any data center
- Yes
- Limitation
- Not applicable to GPU
Download OpsPilot
OpsPilot is rolling out to select GPU operators. Public downloads are coming soon.
OpsPilot is launching to general availability
We’re onboarding early customers now. Get in touch to join the private preview or be notified at launch.
Request early accessAbout XPerf Inc.
Founded by ex-Intel engineers with extensive experience deploying clusters with thousands of accelerators, XPerf Inc. is the control plane for data centers — AI infrastructure software for GPU cluster performance validation and optimization, taking an AI-native approach to cluster operation problems. Austin / Round Rock, Texas.



